图解 JavaScript 之生成器和迭代器
目录
生成器
ES6 引入了一个很酷的东西,叫做 生成器(generator)函数 。每当我问人们有关生成器函数的问题时,得到的回复基本上都是:“我曾看到过一次,没搞明白,然后就再也没有看到过”,“哦,天哪,我读过很多有关生成器函数的博客文章,但依然还没有搞明白”,“我是搞明白了,但是为什么有人会用它啊?”,🤔也许那只是我一直在与自己进行的对话,因为那是我很长一段时间以来习惯的思考方式!但是生成器函数是真的很酷。
那么,什么是生成器函数(generator functions)呢?下面,我们先来看一个函数。👵🏼
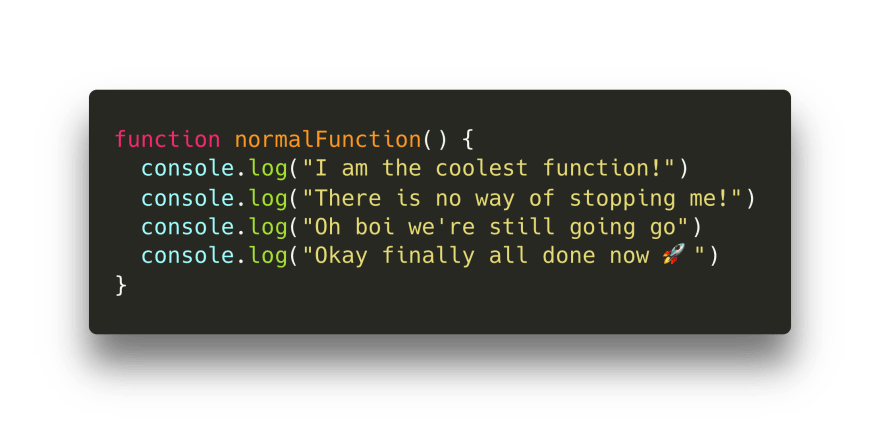
是的,这绝对没什么特别的!它只是一个普通函数,会输出值 4 次。下面我们来调用这个函数!
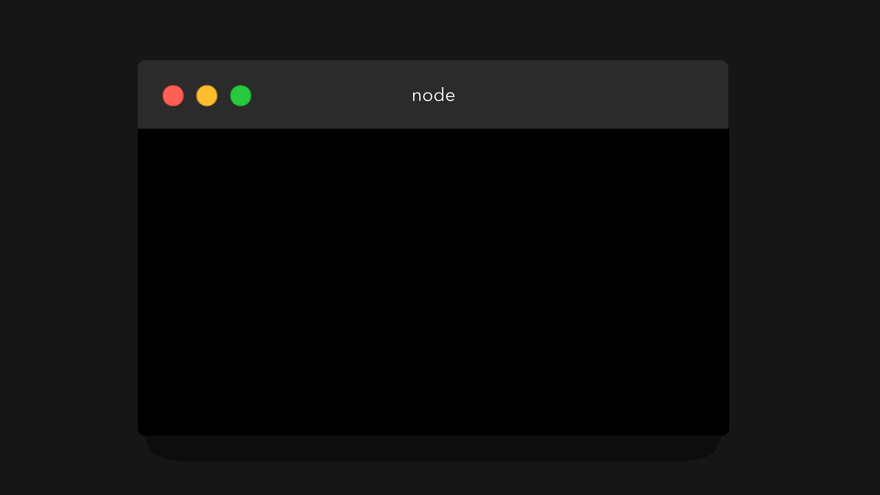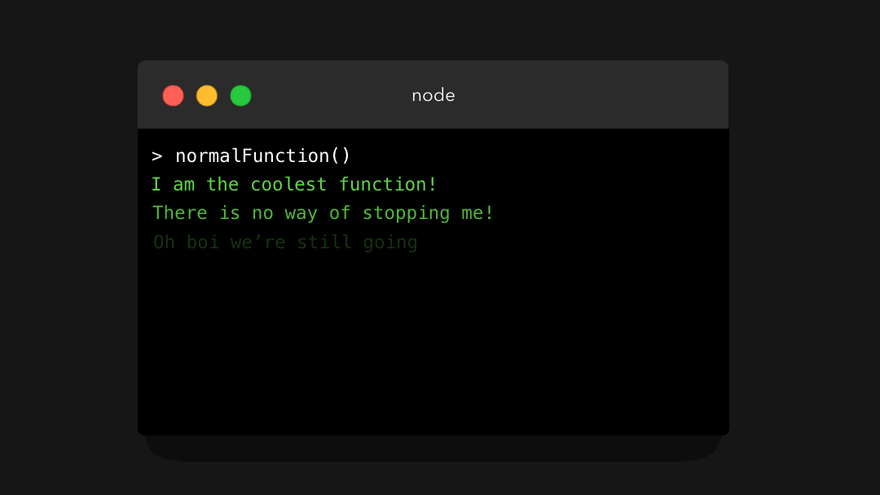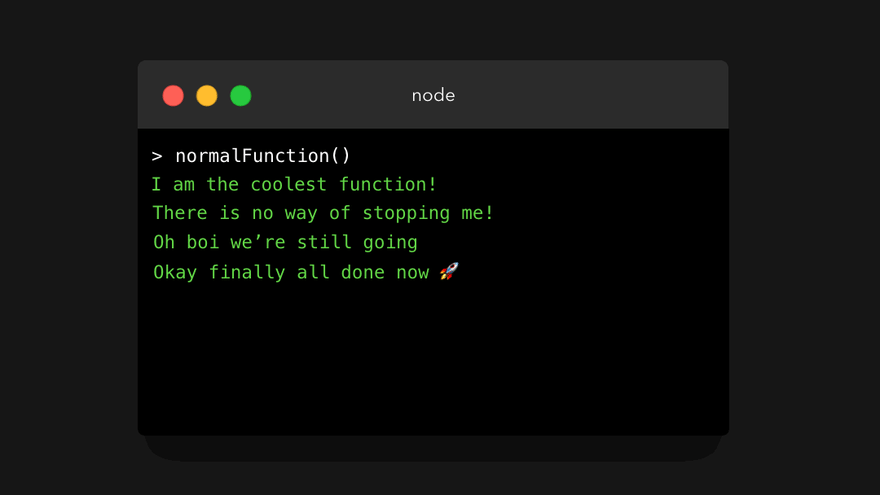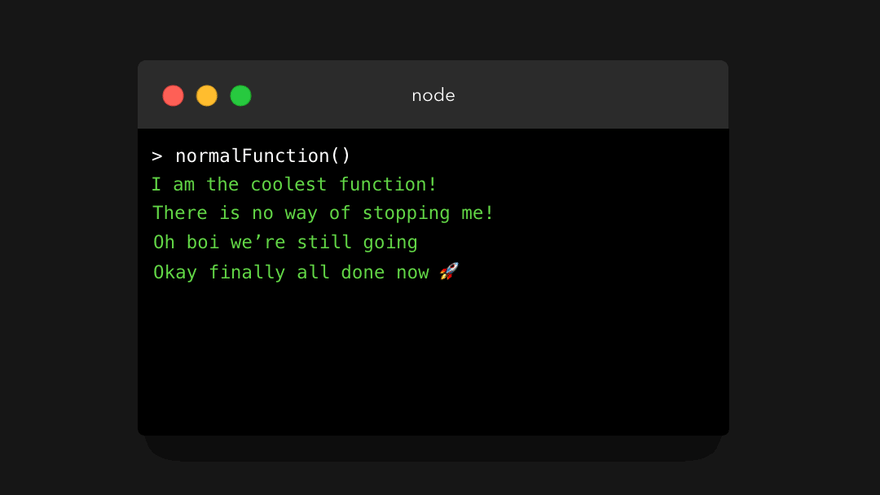
“但是,为什么你要浪费我 5 秒钟的时间让我看看这个没劲的普通函数呢?”,这是一个很好的问题。普通函数遵循一种称为运行至完成(run-to-completion)的模型:当我们调用一个函数时,它将一直运行,直到完成为止(除非某处出错了)。我们不能随意在中间的某个位置暂停(pause)一个函数。
现在最酷的部分来了:生成器函数不遵循运行至完成模型! 🤯这是否意味着我们可以在执行某个生成器函数时随机将其暂停呢?嗯,差不多吧!下面我们看看什么是生成器函数,以及如何使用它们。
我们通过在关键字 function 后加上一个星号 * ,来创建一个生成器函数。

但这不是我们要用生成器函数所要做的全部!与常规函数相比,生成器函数实际上以完全不同的方式工作:
- 调用生成器函数会返回一个 生成器对象(generator object),这个对象是一个迭代器(iterator)。
- 我们可以在生成器函数中使用
yield关键字来暂停执行。
但这到底意味着什么?!
我们先看看第一条:调用生成器函数将返回一个 生成器对象 。当调用常规函数时,函数体将被执行,并最终返回一个值。但是,当调用生成器函数时,会返回生成器对象!下面我们来看看输生成器函数的返回值时是什么样子。
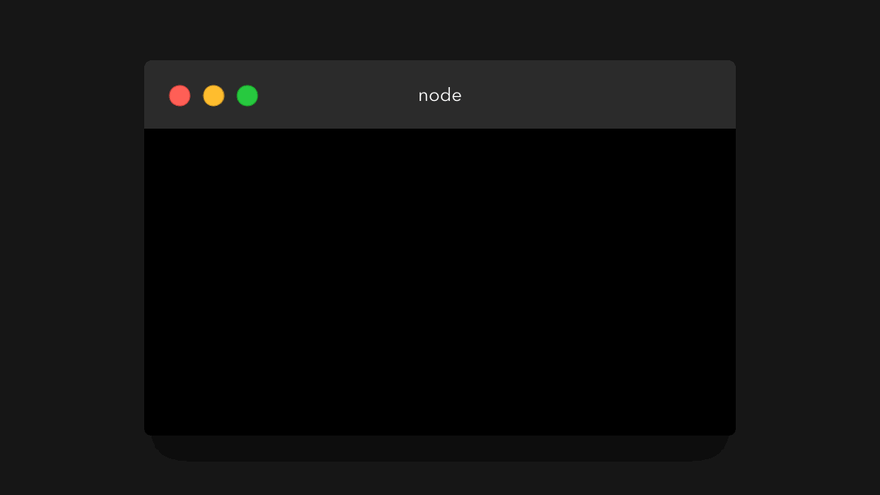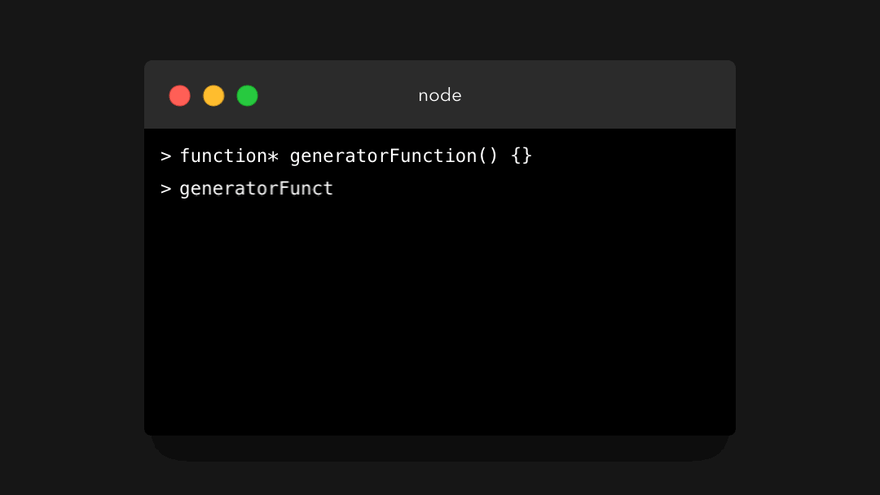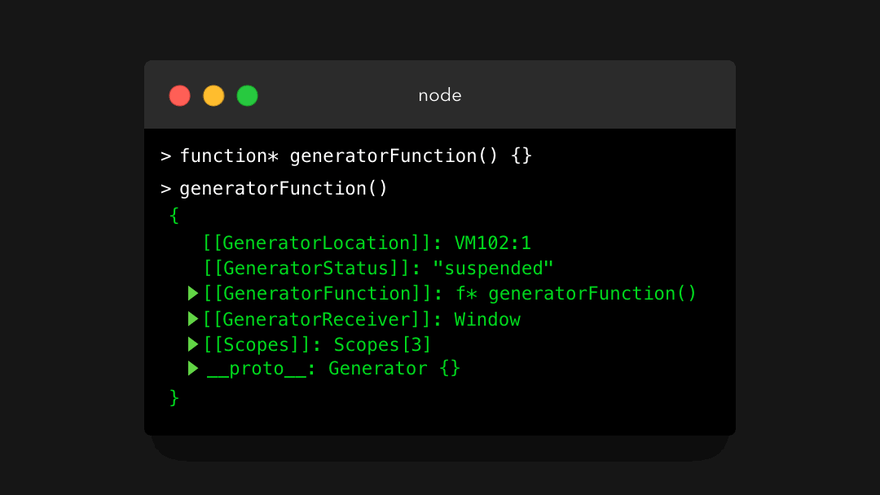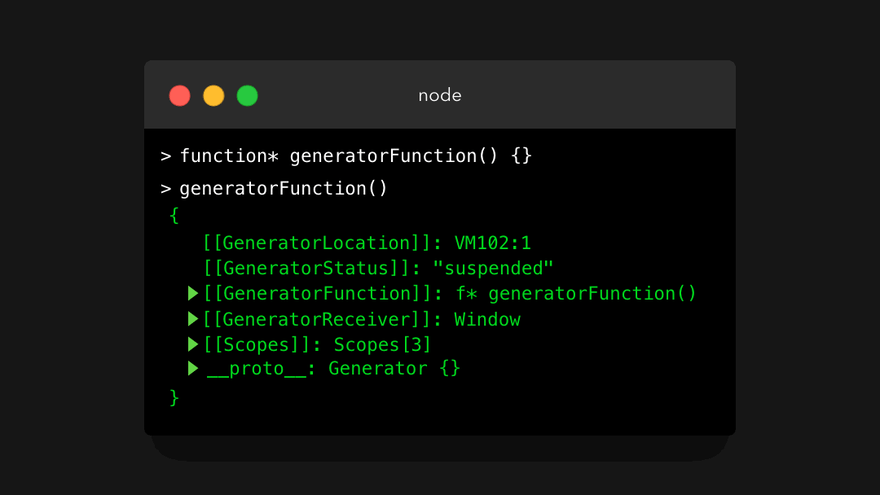
现在,我可以听到你内心在尖叫(甚至发出声了🙃),因为这看起来有点让人难以承受。但是别担心,我们实际上不必用你在这里看到的任何属性。那么,生成器对象有什么好处呢?
首先,我们需要退后一小步,并回答常规函数和生成器函数之间的第二个区别:我们可以在生成器函数中用 yield 关键字来 “暂停” 函数的执行。
使用生成器函数,我们可以编写如下代码( genFunc 是 generatorFunction 的缩写):

这里的 yield 关键字是做什么的呢?当引擎遇到 yield 关键字的时候,生成器的执行将被 “暂停” 。而且最棒的是,下次运行该函数时,它会记住它先前暂停的位置,然后从那里开始运行!😃 那么,下面基本上就是运行该函数时要发生的事情(不要担心,稍后会对此进行动画演示):
- 第一次运行时,它在第一行 “暂停”,并生成字符串值
'✨'。 - 第二次运行时,它在上一个
yield关键字的行开始,一直向下运行,直到遇到第二个yield关键字,并生成值'💕'。 - 第三次运行时,它在上一个
yield关键字的行开始,一直向下运行,直到遇到return关键字,然后返回值'Done!'。
但是... 我们在前面看到的是:如果调用生成器函数,返回的是一个生成器对象,那么如何调用这个生成器函数呢?🤔 这就是生成器对象发挥作用的地方!
生成器对象(在原型链上)包含一个 next() 方法。我们就是用这个方法来迭代生成器对象。但是,为了记住它之前在生成一个值后中断的地方的状态,我们需要将生成器对象赋值给一个变量。我会把这个变量简称为 genObj ( generatorObject 的简称)。
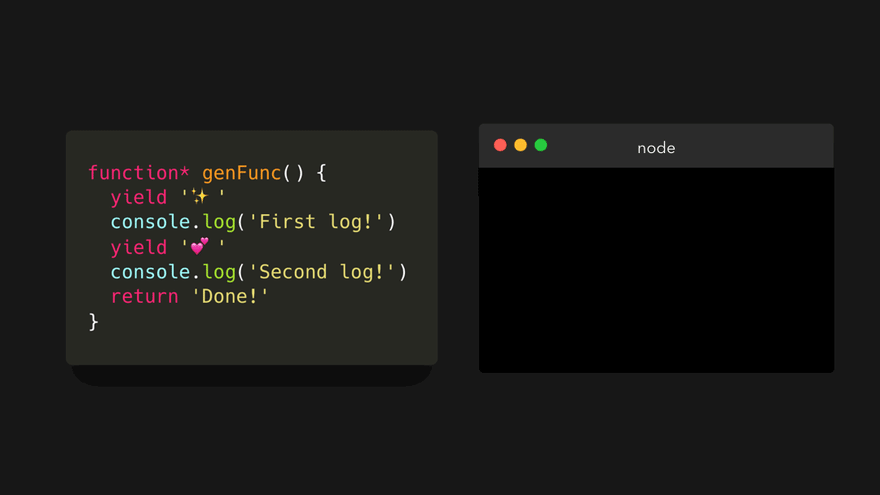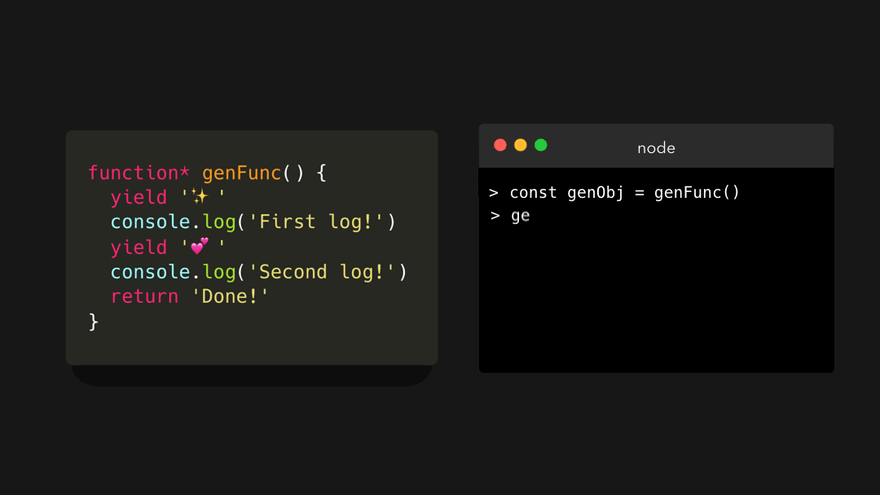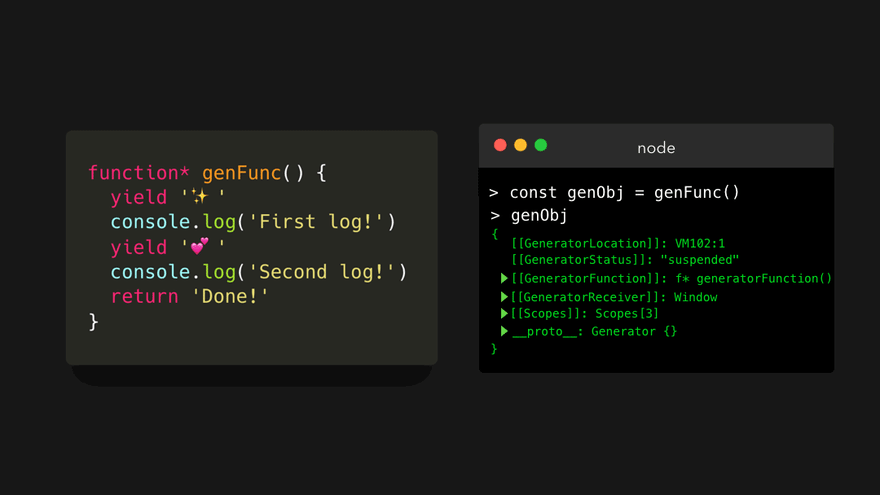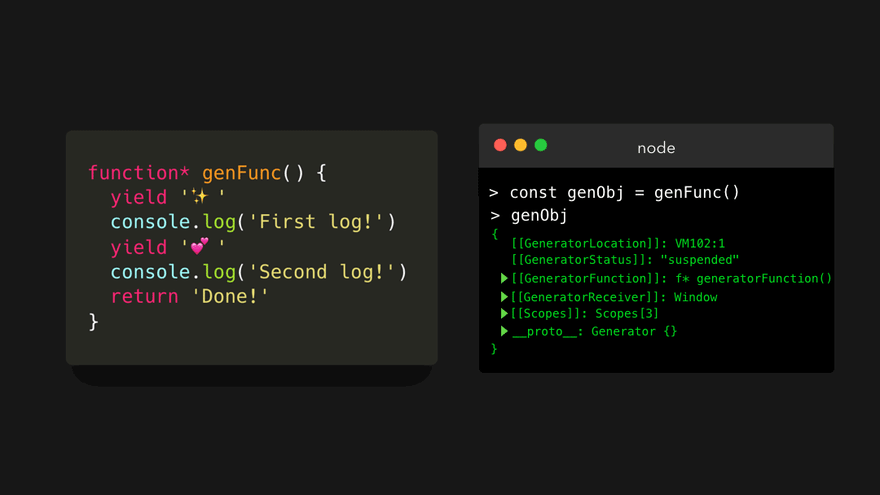
下面我们看看在生成器对象 genObj 上调用 next() 方法时会发生什么!
生成器会一直运行,直到遇到第一个 yield 关键字,而这里这个关键字恰好在第一行!它 ** 生成(yield)** 了一个包含 value 属性和 done 属性的对象 { value: ... , done: ... } :
value属性等于我们生成(yielded)的值。done属性是一个布尔值,仅在生成器函数返回(returned)一个值(不是生成!😊)后,才设置为true。
我们停止了遍历生成器,这让函数看起来像是暂停了一样!这多酷啊。下面我们再次调用 next() 方法!😃
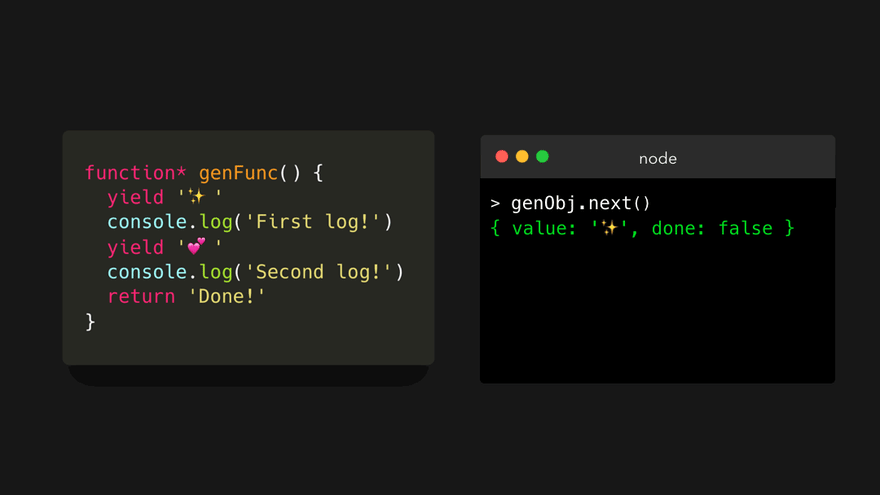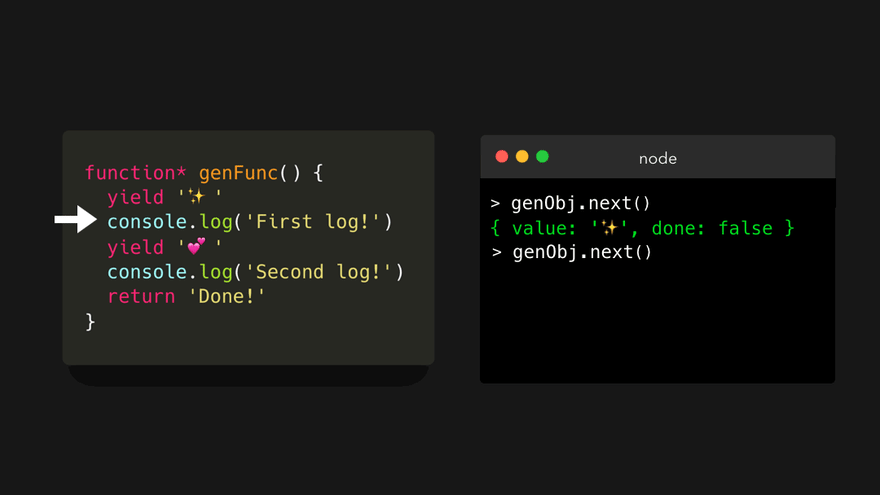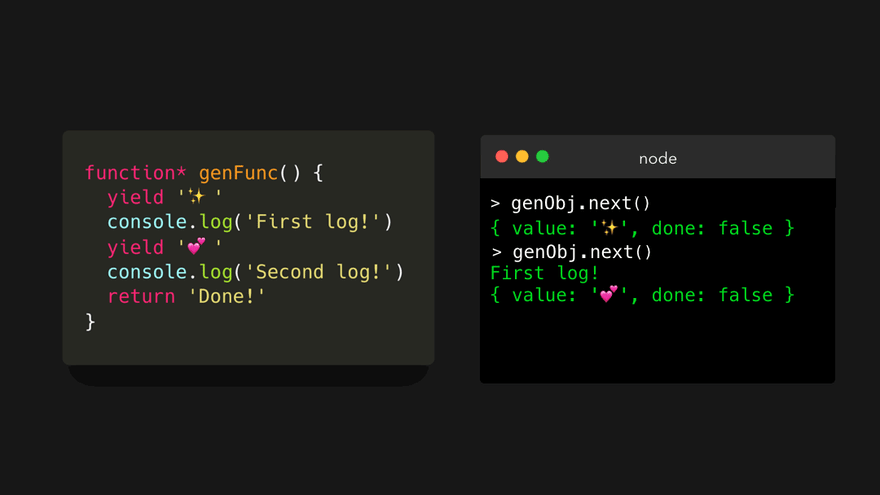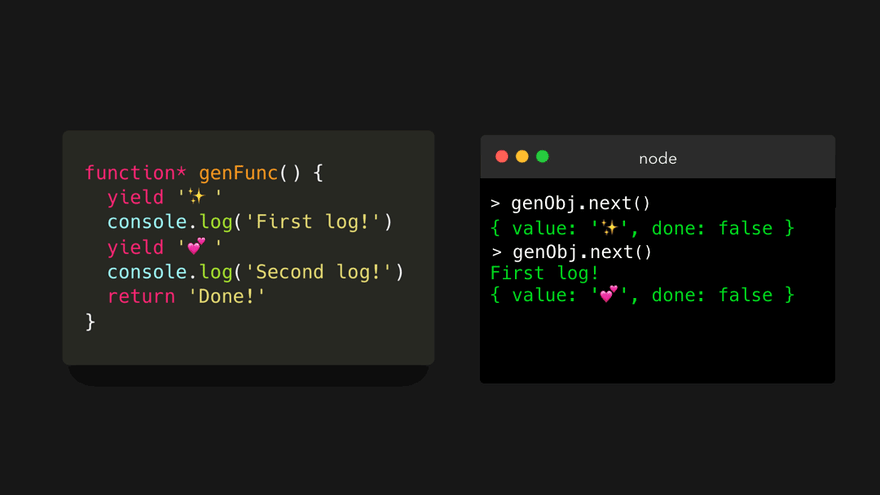
首先,输出字符串 First log! 到控制台中。这条语句既没有 yield 也没有 return 关键字,所以引擎会继续往下执行!然后,遇到了一个 yield 关键字,其值为 '💕' 。这样就生成了一个对象,其 value 属性的值是 '💕' , done 属性的值为 false ,因为我们还没有从生成器中返回。
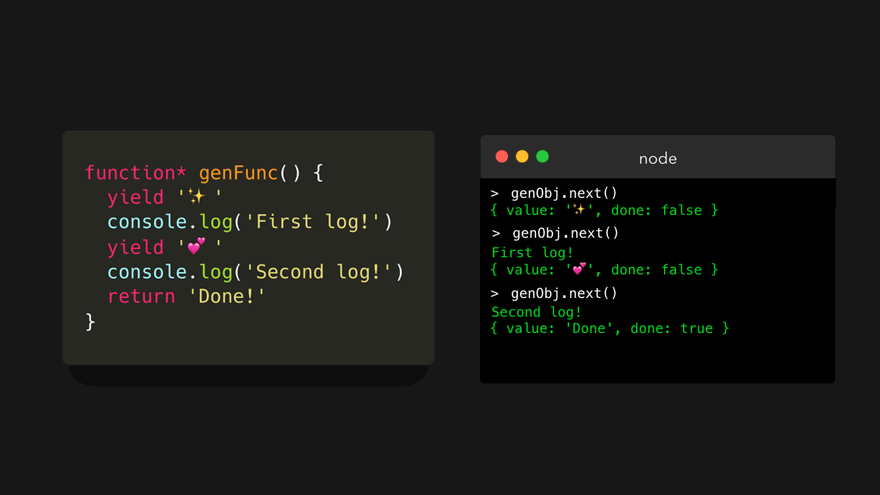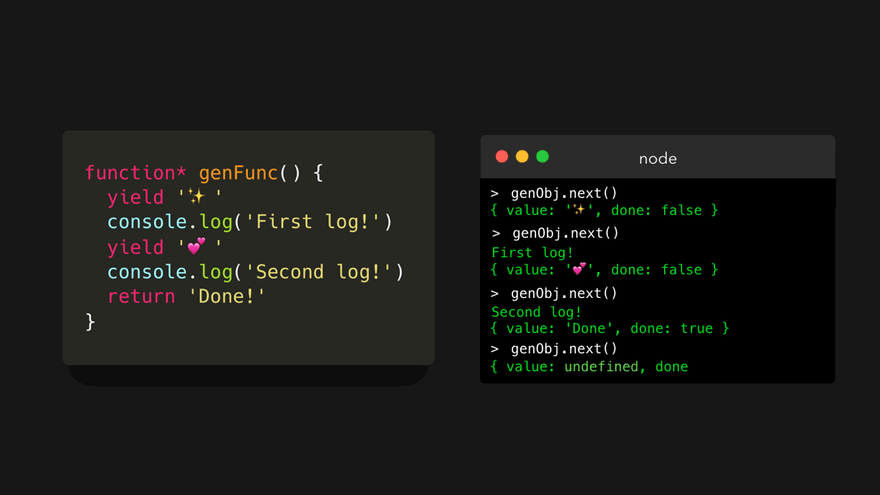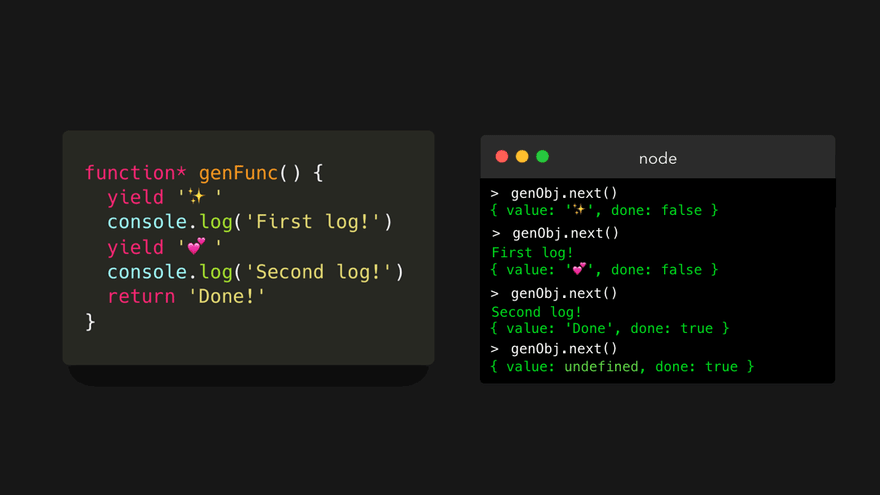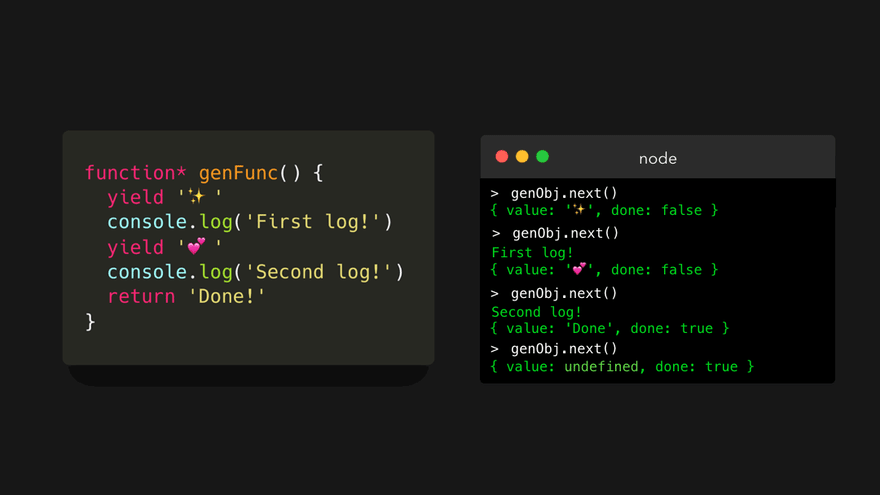
快结束了!下面我们最后一次调用 next() 。

字符串 Second log! 被输出到控制台。然后,引擎遇到一个返回值为 'Done!' 的 return 关键字。引擎返回一个对象,该对象的 value 属性值为 'Done!' 。这次我们是实际返回了,所以 done 属性值被设置为 true !
done 属性实际上非常重要。我们只能一次迭代一个生成器对象。什么?那么当我们再次调用 next() 方法时会发生什么呢!
它只是永远返回 undefined 。如果要再次迭代,必须创建一个新的生成器对象!
迭代器
如我们所见,生成器函数返回一个迭代器(iterator)(生成器对象)。但是.. 等等,迭代器 ?这是否意味着我们可以在返回的对象上用 for...of 循环以及扩展运算符(spread operator)呢?是的!🤩
下面我们试着用 [...] 语法,将生成的值扩展到一个数组中。

或者也许可以用 for...of 循环?!

哎呀,这么多可能性!
但是是什么让迭代器成为迭代器呢?我们之所以可以在数组、字符串、map 和 set 上用 for...of 循环和扩展语法,实际上是因为它们实现了迭代器协议(iterator protocol): [Symbol.iterator] 。假设我们有以下值(带有很具描述性的名称💁🏼♀️):

array 、 string 和 generatorObject 都是迭代器!下面我们来看看它们的 [Symbol.iterator] 属性的值。

但是,不可迭代的值上的 [Symbol.iterator] 的值会是什么呢?
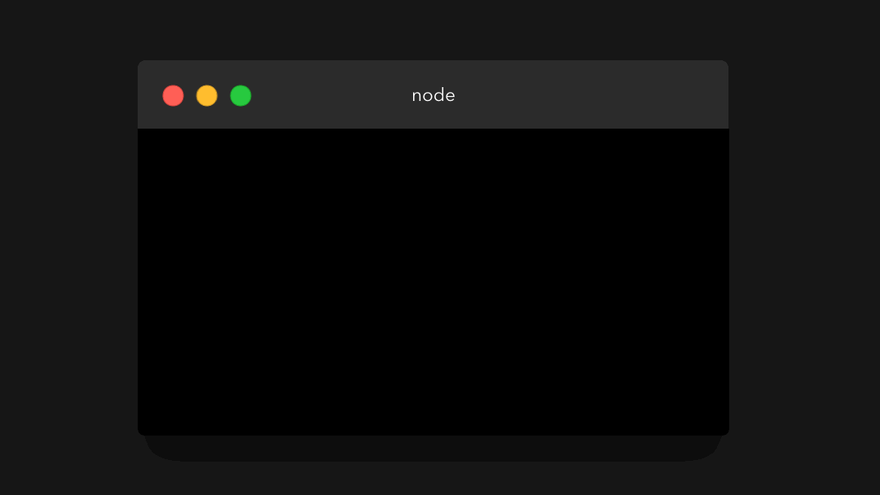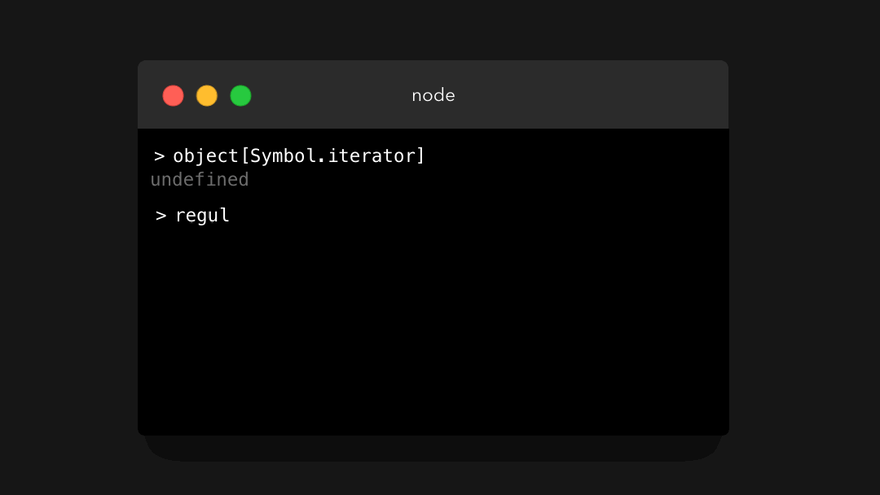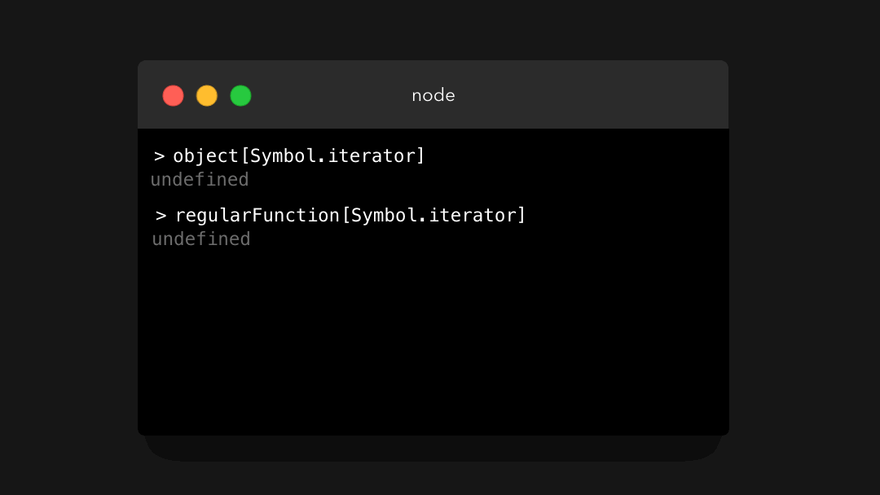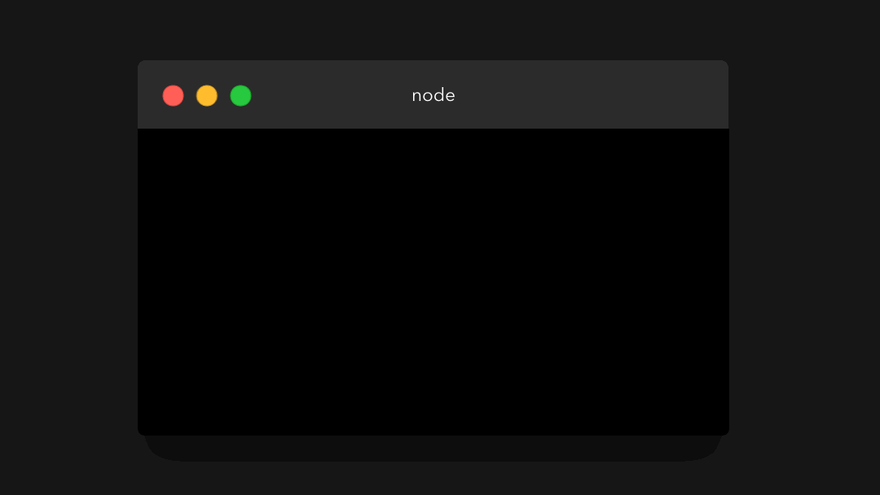
是的,不可迭代的值就没这个属性。那么.. 我们能不能在不可迭代的值上手动添加一个 [Symbol.iterator] 属性,让不可迭代的值变成可迭代的呢?是的,我们可以!😃
[Symbol.iterator] 必须返回一个迭代器,该迭代器包含一个 next() 方法,该方法返回一个对象,这个对象跟我们之前看到过的一样: { value: '...', done: false/true } 。
为简单起见,我们可以简单地将 [Symbol.iterator] 的值设置为一个生成器函数,因为这样做默认就返回一个迭代器。下面我们让 object 变成可迭代的,并且让生成的值是这个完整的对象:

现在看看我们在我们的 object 对象上使用扩展语法或者 for...of 循环会发生什么!

或者也许我们只想获取对象的键。哦,那很容易,我们只需要生成 Object.keys(this) 而不是 this !

我们试一下。

搞定! Object.keys(this) 是个数组,所以生成的值也是一个数组。然后我们把这个生成的数组扩展到另一个数组中,结果就得到一个嵌套的数组。我们并不想要这个,只是想生成每个单独的键!
好消息!🥳 我们可以用 yield* 关键字在生成器中的迭代器中生成单个值,所以 yield 带了一个星号!假设我们有一个生成器函数首先生成一个鳄梨(avocado),然后我们想分别生成另一个迭代器的值(在本例中是一个数组)。我们可以用 yield* 来做到这一点。然后我们委托给另一个生成器!

在继续迭代 genObj 迭代器之前,被委托的生成器的每个值都生成了。
这正是为了单独得到所有对象的键所需要做的!

观察者函数
生成器函数的另一种用法,是我们可以(在某种程度上)将它们用作为观察者函数(observer functions)。生成器可以等待传入的数据,并且只有当该数据被传递过来时,才会处理它。比如:

这里最大的区别是我们不是只有前一个例子中所看到的 yield [value] ,而是将其赋值给一个称为 second 的值,并生成值字符串 First! 。这是第一次调用 next() 方法时会生成的值。
下面我们来看看第一次在可迭代的值上调用 next() 方法时会发生什么。

首先遇到第一行上的 yield ,并生成值 First! 。那么,变量 second 的值是什么呢?
变量 second 的值实际上是下次我们调用 next() 方法时传递给该方法的值!这一次,我们给 next() 方法传一个字符串 'I like JavaScript' 。
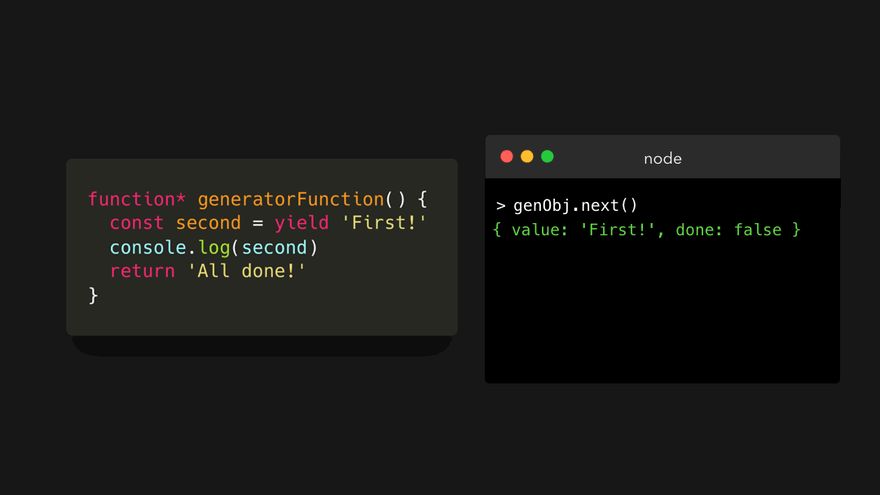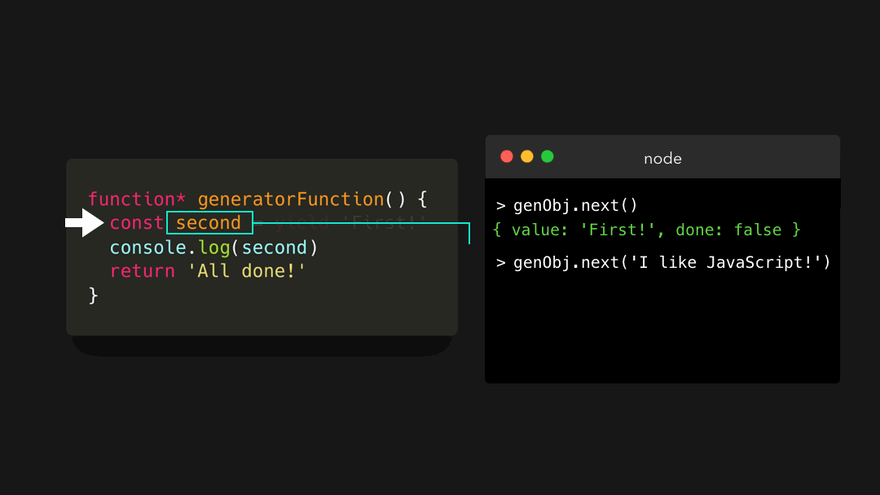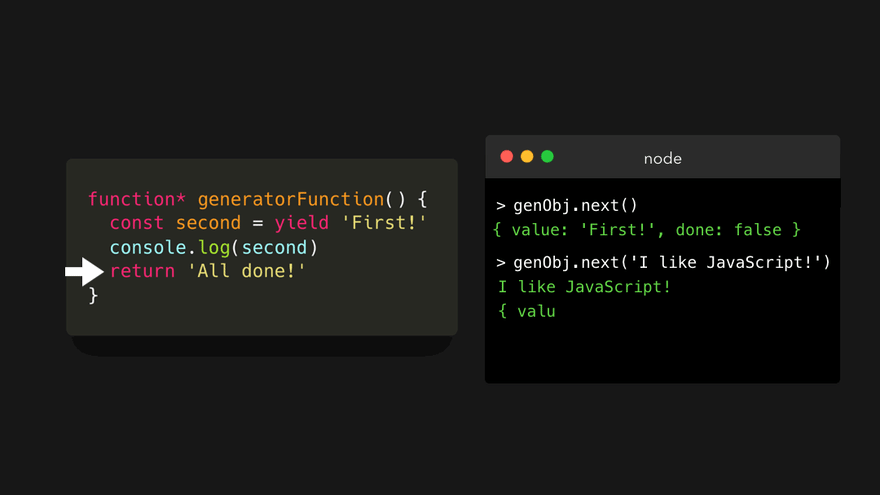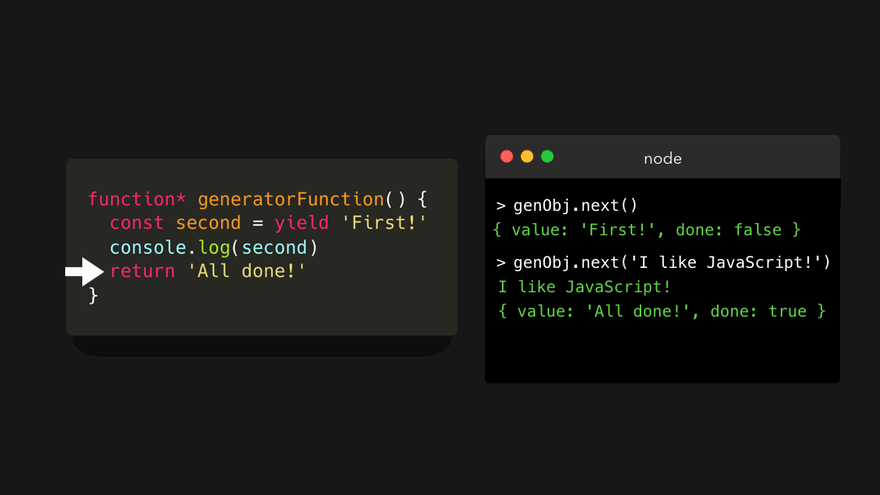
重要的是,在这里看到, next() 方法的第一次调用没有记录任何输入。我们只是通过第一次调用来启动观察器。生成器在继续之前,等待我们的输入,并可能处理我们传递给 next() 方法的值。
那么,为什么我们会想用生成器函数呢?
生成器的最大优点之一就是它们是懒求值(lazily evaluated)的。也就是说,在调用 next() 方法后返回的值仅在我们明确要求后才计算!普通函数没有这种功能:所有值都为我们生成了,以防将来某个时间需要用到它。
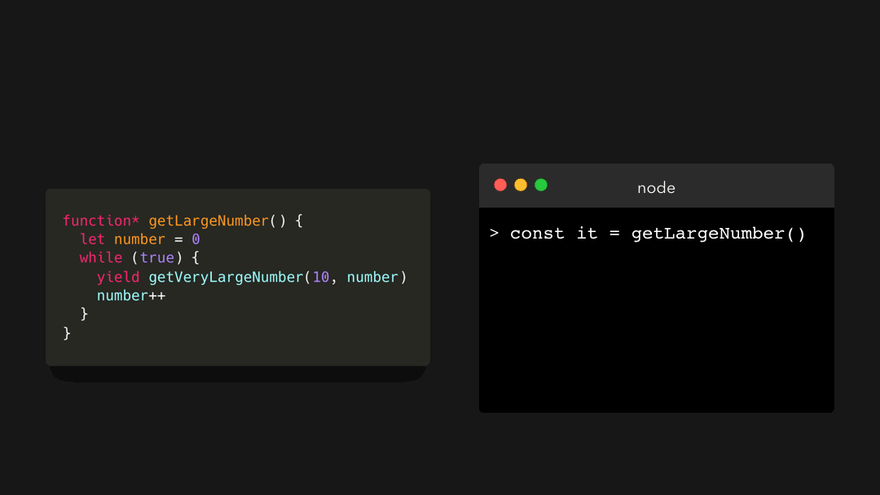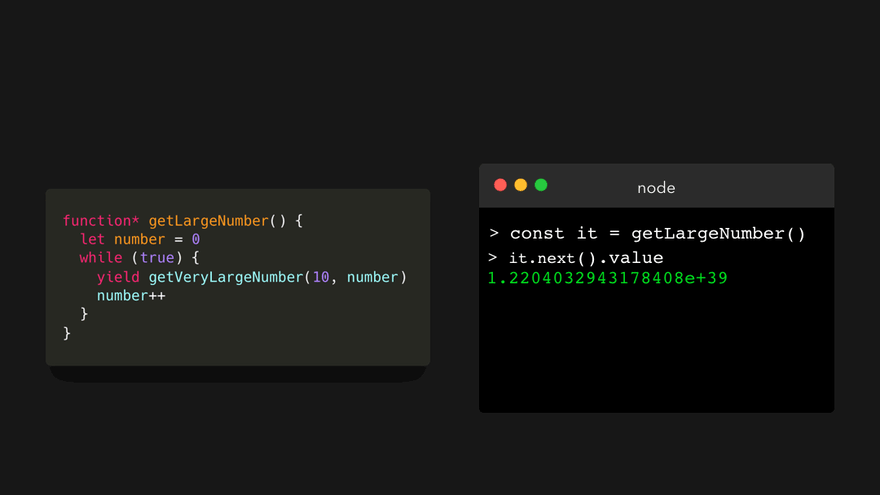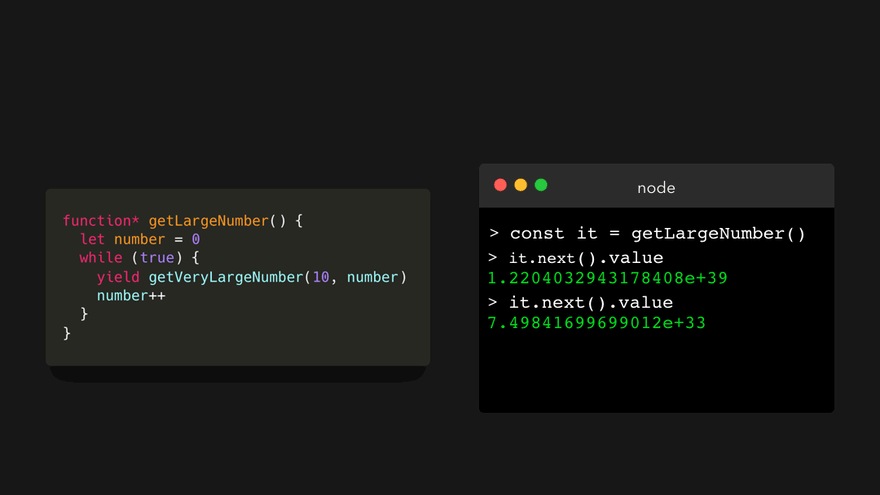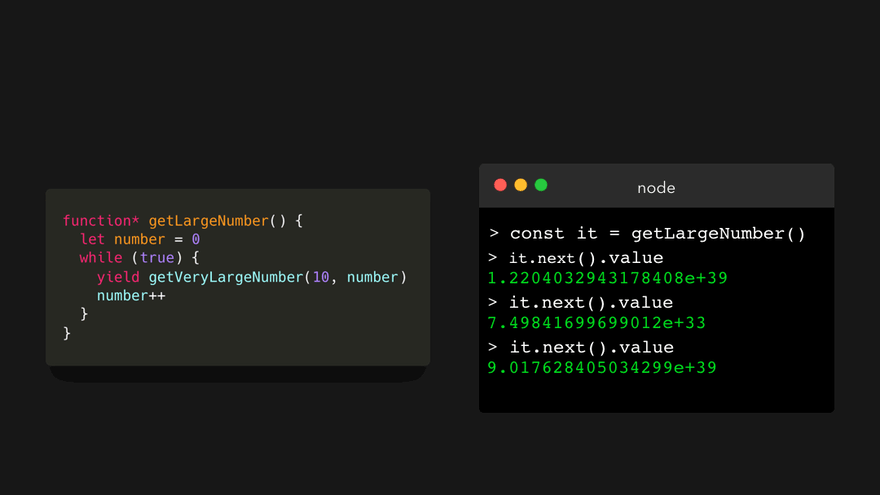
案例
还有其它几个案例,但是我通常喜欢这样做,以便在迭代大型数据集时能更好地控制!
想像一下,我们有一个读书俱乐部清单!📚为简单起见,每个读书俱乐部只有一个成员。一名会员目前正在读几本书,这些书以数组 books 来表示!
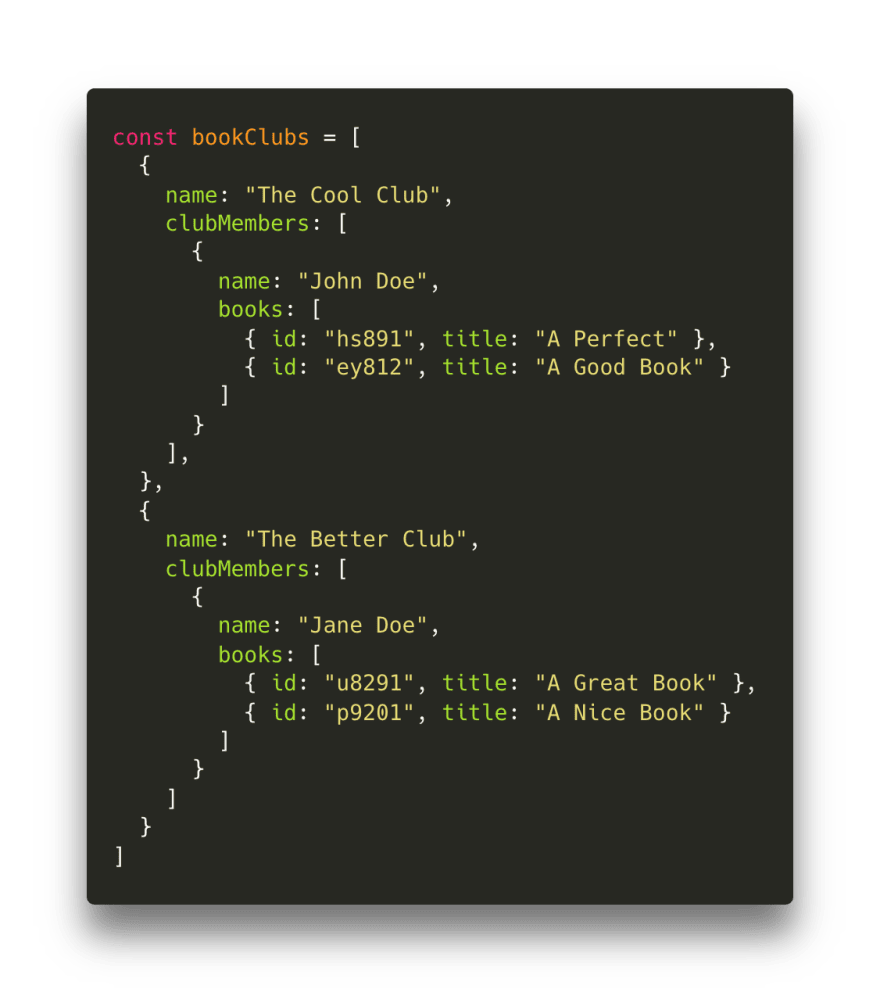
现在,我们在找一本 id 为 ey812 的书。为找到这本书,我们可能只用一个嵌套的 for 循环或者一个 forEach 辅助器,但是这意味着我们得遍历所有数据,即使已经找到了要找的俱乐部会员之后也会继续遍历下去。
关于生成器,很棒的事情是,除非我们告诉它去运行,否则它不会继续运行。也就是说,我们可以评估每个返回的条目,如果是我们正在找的条目,就不需要调用 next() 了。下面我们看看是啥样子。
首先,创建一个生成器,遍历每个会员的 books 数组。我们把会员的 books 数组传给该函数,遍历该数组,并生成每本书!

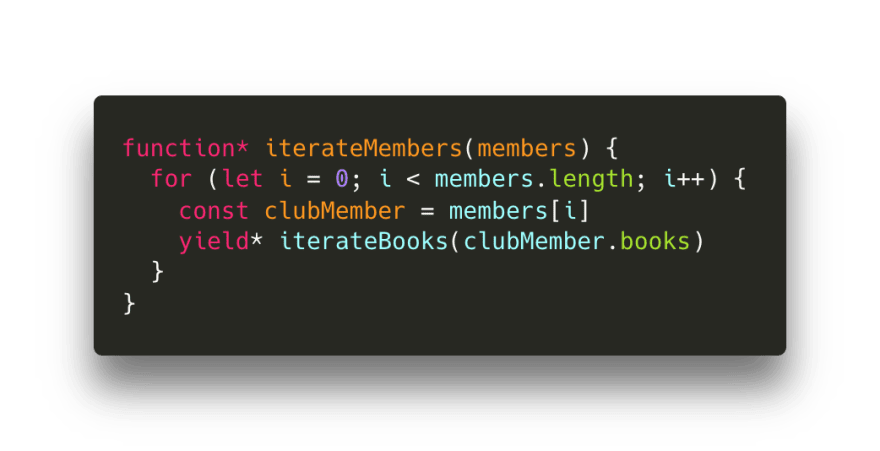
完美!现在我们必须创建一个遍历俱乐部会员数组( members )的生成器。我们实际上并不关心俱乐部会员本身,只是需要遍历他们的书。在 iterateMembers 生成器中,我们委托 iterateBooks 迭代器生成成员们的书!
差不多了!最后一步是遍历读书俱乐部数组( bookclubs )。跟上个例子一样,我们实际上并不关心读书俱乐部本身,只关心俱乐部会员(特别是会员们的书)。下面我 们委托给 iterateMembers 迭代器,并把 clubMembers 数组传给它。
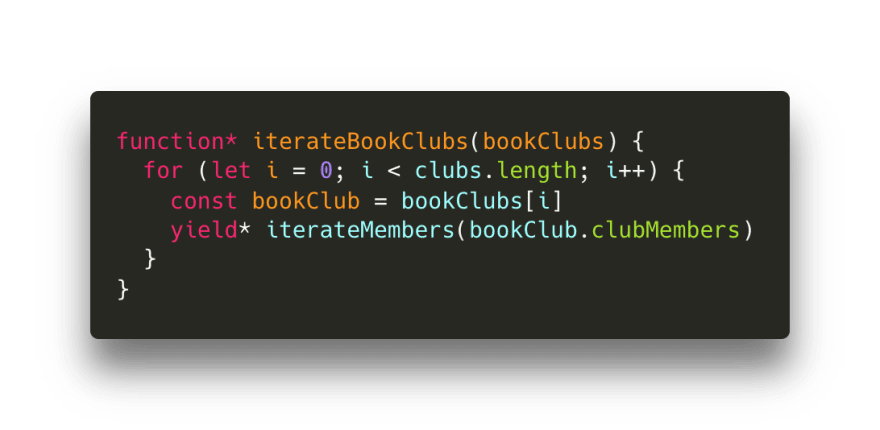
为遍历所有这些东西,我们需要通过将 bookClubs 数组传递给 iterateBookClubs 生成器,让生成器对象可迭代。我现在暂时将其称为生成器对象 it 。
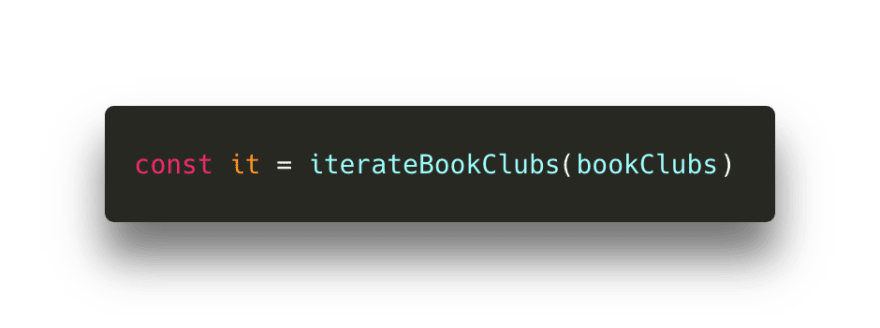
下面我们调用 next() 方法,直到得到 id 为 ey812 的书。

不错!现在为了得到要找的书,我们就不需要遍历所有数据,而是只按需查找数据!当然,每次都要手动调用 next() 方法效率不是很高,所以我们来做一个函数吧!
下面将我们要找的书的 id 传给该函数。如果 value.id 是我们要找的 id,那么就只返回整个 value (book 对象)。否则,如果不是要找的 id ,就再次调用 next() !
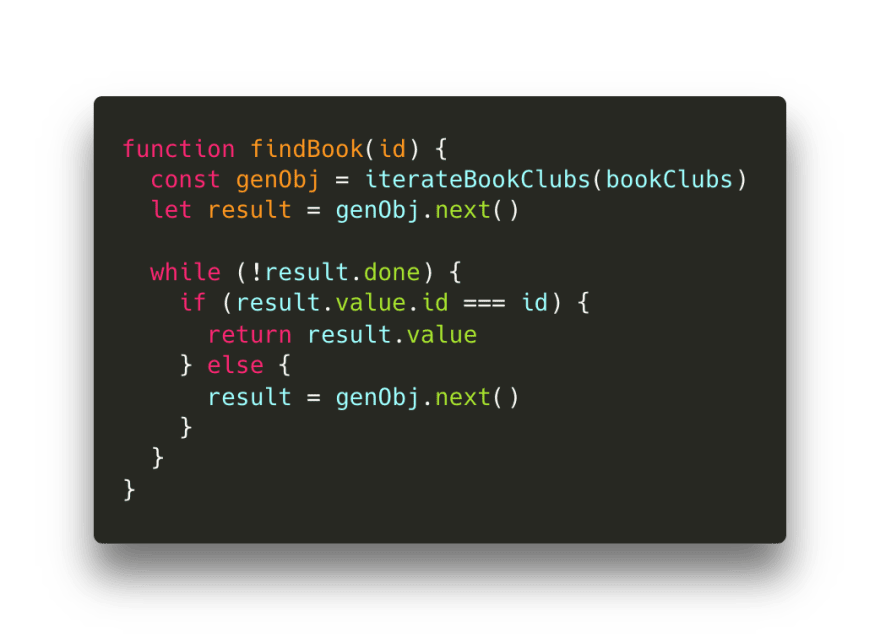

当然,这只是一个很小很小的数据集。不过,试想一下,假如我们有成千上万的数据,或者可能是一个传入的流,为了只找到一个值,我们需要解析。通常,我们必须等待整个数据集准备就绪,才能开始解析。而用生成器函数,我们可以只需要小部分数据,检查该数据,然后只在我们调用 next() 方法时候才会生成值!
如果你仍然处于懵逼状态,不要担心。虽然生成器函数确实相当难以理解,但是只要亲自用过它们,并且有一些可靠的案例,那就没那么难了。