Ignition 设计文档
Ignition: V8 解释器。
目录
译注
由于原作者编写该文档至今被翻译出来过去了两年多的时间,文中提到的一些变动计划都已经实施和完成。比如说:在 2017 年时已完全废弃并移除了 full-codegen 和 Crankshaft。
1. 背景
V8 的 full-codegen 编译器生成的机器码是很冗余的,正因为如此,它使 V8 堆内存的占用在普通网页中明显增加(之前的分析表明,生成的代码空间占用了 15-20% 左右的 JS 堆内存)。
由于引起了内存压力,这意味着 V8 将努力避免生成那些它认为可能不会被执行到的代码。对此 V8 实现了延迟解析和编译,一般情况下函数只会在第一次运行时被编译。这个做法在网页启动时耗时非常明显,因为在延迟编译过程中函数的源代码需要被重新解析(例如:http://crbug.com/593477)。
Ignition 项目的目标是为 V8 建立一个解释器来执行低层级的字节码,以便让那些只被运行一次或者非热点的代码以字节码的形式更紧凑地存储。由于字节码更小,编译时间也将大幅减少,我们也能在初始编译时更激进,以此来明显地改善启动时间。还有一个额外的优势:字节码可以被直接丢给 TurboFan 图生成器,从而在 TurboFan 里面优化函数时,可以避免重新解析 JavaScript 源代码。
Ignition 项目的目标有:
- 将代码空间大小减小至当前的 50% 左右;
- 与 full-codegen 相比有合理的性能(在某些峰值性能基线测试,如 Octane 中,慢 2 倍以内;在真实世界的网站中,要变慢少一些)
- 注:由于热点代码会被 Crankshaft 或者 TurboFan 优化,整体性能下降应该会少得多,期望是可以忽略。
- 完整地支持 DevTools 调试和 CPU 性能分析;
- 替代 full-codegen 成为第一层编译器;
- 我们不能完全替换 full-codegen,直到 Crankshaft 被完全废弃,因为 Crankshaft 不能解优化到 Ignition,它只能解优化到 full-codegen 的代码。
- 作为 TurboFan 编译器的一个新的前端,要能在重新优化编译时,不必重新解析 JS 源代码;
- 支持从 TurboFan 解优化到 Ignition 解释器。
明确不是当前项目(至少现阶段)的目标有:
- 支持不允许 JIT 代码的平台(比如 iOS) ** IC 和 code stub 仍然需要生成 JIT 代码。*
- 支持非 JavaScript 代码执行 (比如 WASM);
- 与 full-codegen 编译器保持同样的性能;
- 完全替换 full-codegen 编译器
- 如上所述,我们需要 full-codegen 作为 Crankshaft 的一个解优化的目标,以及为 Chankshaft 生成 Ignition 所不能提供的类型信息。因此,full-codegen 将成为那些最终被 Crankshaft 优化的热点代码的中间层(任何被语法分析器决定需要被 TurboFan 优化的函数,将不会使用 full-codegen 去编译,它们将被 TurboFan 直接优化)。
2. 总体设计
本节概述了 Ignition 字节码解释器的总体设计,后面的章节则介绍了更多详细的细节信息。
Ignition 解释器本身由一系列字节码处理程序代码片段组成,每个片段都处理一个特定的字节码,然后调度给下一个字节码的处理程序。这些字节码处理程序使用高层级的、机器架构无关的汇编代码写成,由 CodeStubAssembler 类实现,并由 TurboFan 编译。
因此,解释器可以被实现一次,然后使用 TurboFan 生成 V8 支持的各种架构的机器码。在启用解释器后,每个 V8 isolate 都包含一个全局的解释器调度表,调度表以字节码的值作为索引,包含着每个字节码处理程序的代码对象指针。这些字节码处理程序可以被放到启动快照中,在新的 isolate 创建时反序列化出来。
为了能被解释器运行,函数在首次非优化编译阶段就被 BytecodeGenerator 转换成字节码。 BytecodeGenerator 属于 AstVisitor ,它遍历函数的 AST (抽象语法树),为每个 AST 节点生成合适的字节码。字节码作为 SharedFunctionInfo 对象中的一个属性来与函数相关联,函数的代码入口地址被设置到内置的 InterpreterEntryTrampoline stub 中。
当函数在被运行时调用到时,也就进入了它的 InterpreterEntryTrampoline stub。这个 stub 会先初始化合适的栈帧,然后为函数的第一个字节码调度到解释器的字节码处理程序,从而在解释器中开始执行该函数。每个字节码处理程序的末尾都会根据下一个字节码,直接通过全局解释器表中的索引值调度到下一个字节码处理程序。
Ignition 是一个基于寄存器的解释器。这些寄存器不是传统意义的机器寄存器,而是在函数的栈帧中分配的寄存器文件 (register file) 中特定的 slot(译注:此处及后面所说的 slot,都指 V8 运行栈中的一小块内存)。根据字节码参数可以指定字节码操作的输入、输出寄存器,字节码参数在字节码数组 ( BytecodeArray ) 流中紧跟着字节码。
为了减少字节码流的大小,Ignition 有一个累加器寄存器,它被很多字节码作为隐式的输入输出寄存器。这个寄存器不是栈上寄存器文件的一部分,而是被 Ignition 保存在机器寄存器中。这样能将重复读写内存的寄存器操作最小化。对于很多操作而言,它同时也可以减少字节码的大小,因为不需要指定输入和输出寄存器。比如,二元操作的字节码,只需要用一个操作数来指定其中一个输入,另一个输入以及输出寄存器被隐式地设置为累加器寄存器,而不需显式地指定所有三个寄存器。
3. 生成字节码处理程序
字节码处理程序由 TurboFan 编译器生成。每个处理程序有它自己的代码对象,并且是独立生成的。这些处理程序通过 InterpreterAssembler 用 TurboFan 图操作写成, InterpreterAssembler 是 CodeStubAssembler 的一个子类,并新增了解释器需要的一些高层级的原函数(比如 Dispatch , GetBytecodeOperand 等)。 Ldar (LoaD Accumulator from Register, 将寄存器加载到累加器) 字节码处理程序的生成器函数如下:
cpp
void Interpreter::DoLdar(InterpreterAssembler* assembler) {
Node* reg_index = __ BytecodeOperandReg(0);
Node* value = __ LoadRegister(reg_index);
__ SetAccumulator(value);
__ Dispatch();
}
1
2
3
4
5
6
2
3
4
5
6
字节码处理程序不是被直接调用的,而是由每个字节码处理程序调度到下一个字节码。在 TurboFan 中字节码处理程序调度作为尾部调用操作。解释器加载下一个字节码,使用索引从调度表中获取目标字节码处理程序代码对象,然后尾部调用该代码对象以调度到下一个字节码的处理程序。
解释器还需要在固定的机器寄存器中维护跨字节码处理程序的状态,比如:指向 BytecodeArray 的指针、当前字节码偏移量,还有解释器中累加器的值。这些值被 TurboFan 视为参数,它们作为前一个字节码调度的输入被接收,并作为字节码调度尾部调用的参数传递给下一个字节码处理程序。字节码处理程序调度规约为这些参数指定固定的机器寄存器,这使得它们可以透过解释器的调度过程,而无需将它们压栈和退栈。
生成字节码处理程序的图后,它通过 TurboFan 管道的简化版本传递,并赋值给解释器表中相应的条目。
4. 生成字节码
要将一个函数编译成字节码,需要先将其 JavaScript 源码解析生成 AST (Abstract Syntax Tree, 抽象语法树)。然后 BytecodeGenerator 遍历抽象语法树,为每个 AST 节点生成合适的字节码。
比如,JavaScript 片段 arr[1] 会被转换成如下的抽象语法树:
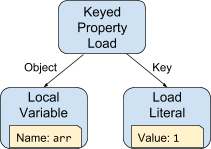
BytecodeGenerator 将遍历这棵树,它首先访问 KeyedPropertyLoad 节点,该节点将首先访问 Object 这条边生成代码,其对对象取值,该对象将被用于按 key 加载取值。在当前的例子中,这个对象是一个局部变量,它已经被赋值到了一个解释器寄存器中(比如 r3),因此这里生成的代码就是将这个寄存器中的值加载到累加器中 ( Ldar r3 ),然后控制权返回到了 KeyedPropertyLoad 节点的访问器。该访问器申请一个临时的寄存器(比如 r6)保存此对象,生成代码将累加器保存到该寄存器中 ( Star r6 ) 【注】 。Key 这条边被访问后,将生成属性加载中 key 部分的代码。当前这个例子中,该节点是一个整数 1,因而生成 LdaSmi #1 字节码将 1 加载到累加器中。最终,输出按 key 加载属性的代码,字节码片段结果如下:
text
Ldar r3
Star r6
LdaSmi #1
KeyedLoadIC r6 <feedback slot>
1
2
3
4
2
3
4
【注】: 由于该对象已经在寄存器中,这里将其从累加器中移入和移出是冗余的,因此,我们有了寄存器别名优化来避免它,下面的 TODO 章节会描述相关细节。(译注:不用往下面找了,原作者没写。)
BytecodeGenerator 使用 BytecodeArrayBuilder 为解释器生成组织良好的字节码数组。 BytecodeArrayBuilder 为原始字节码的生成提供了灵活性。比如,我们可以使用多个字节码来实现相同的语义操作,但包含不同宽度(如 16 位或者 32 位)的操作数。 BytecodeGenerator 不需要知道任何这些,它只需要简单地让 BytecodeArrayBuilder 输出包含一系列操作数的指令字节码, BytecodeArrayBuilder 会为这些操作数选择合适的宽度。
在字节码生成完成后,它被存到了 SharedFunctionInfo 的一个属性中。同解释器执行代码一样,字节码所表示的,足以生成 TurboFan 编译器的图,而不需要重新去生成函数的抽象语法树。这个避免了在重新编译之前需要去重新解析该函数的 JavaScript 源码。
4.1 解释器寄存器分配
在字节码的生成过程中, BytecodeGenerator 从函数的寄存器文件中为局部变量、Context 对象指针(用于维护跨函数的闭包状态)、表达式求值中的临时变量(表达式栈)分配寄存器。在执行时,寄存器文件的空间作为函数栈帧的一部分在函数的序幕中被分配出来。字节码通过指定特定寄存器的索引作为操作数来操作这些寄存器,解释器使用该操作数加载或存储(数据)到与寄存器相关联的特定 stack slot (栈里面的一块内存)。
由于寄存器索引直接映射到了函数栈帧的 slot 上,解释器也可以将栈上的其它 slot 作为寄存器访问。比如,函数的 Context 和函数的闭包指针,它们在序幕中被压到了栈上,可以在任何包含寄存器操作数的字节码中,直接使用 Register::current_context() 和 Register::function_context() 访问。类似的,传递给函数的参数(包括隐式 this 参数)也可以通过寄存器访问。
下图展示了一个函数的示例栈帧,以及寄存器索引和它们原始操作数的值在 stack slot 上的映射关系:

由于使用了这种寄存器文件的方式,Ignition 不需要和 full-codegen 一样在表达式求值时,动态地在栈上 push 和 pop 数据(唯一例外的是,在函数调用时需要将参数压栈,不过这是在一个独立的内置函数中完成,不是在解释器中)。这样有一个好处:栈帧在函数的序幕中可以被一次性分配出来,并与机器架构保持特定的对齐要求(比如,Arm64 要求栈 16 字节对齐)。然而,这意味着 BytecodeGenerator 在代码生成期间,需要计算每个栈帧所需要的最大大小。
函数内部声明的局部变量,在语义上被语法解析器提升到了函数的顶部。这样可以提前知道局部变量的个数,在 AST 遍历的初始阶段就可以在寄存器文件中为每个局部变量分配索引。语法解析器同样也可以提前知道内部 Context 需要的额外寄存器数量,并且在 AST 遍历的初始阶段用 BytecodeGenerator 分配出来。
表达式求值过程中需要临时变量,在表达式树中可能需要有一个或多个活动寄存器来保存中间值,直到它们被使用完毕(才可以被释放)。 BytecodeGenerator 使用作用域范围的 BytecodeRegisterAllocator 来分配寄存器。在每个声明中,会为之创建一个新的作用域分配器,作用域分配器被用于内部表达式节点分配临时寄存器。这些临时寄存器仅在表达式的生命周期内有效,也就是说当 BytecodeGenerator 访问完这个表达式后,这个作用域分配器将超出范围,它分配的所有临时寄存器将都被释放掉。 BytecodeGenerator 在整个函数的代码生成过程中,保持着记录被分配出的临时寄存器的最大个数,然后在寄存器文件中为所需要的最大临时寄存器数量分配出足够多的扩展 slot。
在寄存器文件的布局中,局部变量后面紧跟着临时变量寄存器,它们之间没有任何重叠,以保持访问简单。在字节码生成器计算出寄存器文件的总大小后,便会使用该大小计算出函数帧所需的大小,函数帧大小被保存到了 BytecodeArray 对象中。
在进入函数时,解释器序幕将栈指针增加需要的大小,以在栈帧上为寄存器文件分配空间。寄存器文件中所有的条目最初都被标记为 undefined_value (同 full-codegen 的序幕中压栈局部变量一样)。解释器在寄存器文件的每个条目中只存放标记指针,这样 GC 就可以将所有条目当成标记指针,以遍历访问栈上任意的寄存器文件。
4.2 Context 链
解释器在 Context stack slot(函数帧中固定的一部分,字节码中使用 Register::current_context() 访问它)中跟踪当前 Context 对象。在一个新的 Context 被分配出来后, BytecodeGenerator 分配一个 ContextScope 对象来跟踪嵌套的 Context 链表。它允许 BytecodeGenerator 展开嵌套的 Context 链表,允许解释器直接访问内层 Context 扩展中分配的任意变量,而不需要遍历 Context 链表。
当 ContextScope 对象被分配出来时, ContextPush 字节码也被生成了。这个字节码将当前 Context 对象移到 BytecodeGenerator 分配的寄存器中,然后将新的 Context 存入当前 Context 寄存器中。在操作局部的 Context 分配的变量时, BytecodeGenerator 先找到与之关联的 ContextScope ,然后找出 Context 对象目前所在的寄存器,然后可以根据这个寄存器指向的 Context 直接在正确的 Context slot 中加载出该变量,而不需要向上遍历 Context 链表来找到正确的 Context。当 ContextScope 超出作用域时,会生成一个 ContextPop 字节码,它会将父 Context 恢复到当前 Context 寄存器中。
通过将当前 Context 维护为确定的寄存器,而不是依赖于 BytecodeGenerator 去跟踪哪个寄存器存放了当前的 Context,以此让解释器能执行那些 “需要当前 Context 的操作”(比如将 Context 传递给 “JS 函数调用” 或者 “运行时内置函数” 的操作),而不必使用一个额外的操作数指定哪个寄存器存放着当前的 Context。
4.3 常量池条目
常量池用于存放字节码中被引用为常量的堆对象和小整数。每个 BytecodeArray 都可以在 BytecodeArray 对象中嵌入它自己的常量池。常量池是由指向堆对象的指针组成的 FixedArray 。字节码使用 FixedArray 中的索引来引用常量池中的常量。这些索引将作为字节码的无符号立即操作数,从而使得常量池中的条目成为字节码的输入。

String 和 heap number (译注:堆数字,指除用 31 位表示的小整数以外的数字,如浮点数、32bit 才能表示的整数等) 始终被放到常量池中,因为它们位于堆中并且通过指针被引用。小整数和强引用的 oddball 类型被字节码直接加载,不会被放到常量池中。常量池还可以存放向前跳转偏移,这个下面会讨论到。
常量池在字节码生成的过程中被创建,由 ConstantArrayBuilder 类负责生成。当字节码需要引用一个常量时,比如说加载一个字符串,它将该字符串对象传给 ConstantArrayBuilder 并且要求为其返回常量池中的一个索引。 ConstantArrayBuilder 检查该对象是否已经存在于数组中,如果存在则直接返回其索引,否则将该对象追加到正在生成的常量池的末尾,然后返回其索引。在字节码生成的最后, ConstantArrayBuilder 生成一个大小固定的 FixedArray 数组,数组中包含了所需的对象指针。
到目前为止,上面所描述的逻辑都相对简单。复杂的地方源自使用常量池存放向前跳转偏移。向前跳转的难点在于,跳转的偏移在字节码生成时是未知的,因此需要在字节码流中为跳转偏移预留空间。 BytecodeArrayBuilder 保持记录这个位置,当知道跳转偏移时就打上补丁。
在简化的情景中,字节码生成器生成一个向前跳转字节码,它的 “单字节立即操作数” 在字节码流中被留空。当知道跳转偏移时,打上补丁。如果偏移值能被放到单字节操作数中,那么该偏移就能被直接写到预留的空白操作数中。如果偏移值比一个字节大,那么偏移将被放到常量池中,然后更新跳转字节码和其操作数:跳转字节码被更新为 “使用常量池作为操作数的跳转字节码”,操作数被更新为常量池中的条目(索引)。
在实际中,常量池会随着代码的生成而增大,并且它的大小没有限制。在生成代码时, BytecodeArrayBuilder 需要知道为向前跳转生成什么样的跳转字节码:单字节操作数、双字节操作数,还是四字节操作数。因此, ConstantArrayBuilder 类支持了常量池条目的预留。它能保证一个特定大小的索引在将来可以被使用,即便索引值当前还不知道。 BytecodeArrayBuilder 在生成向前跳转时创建一个预留操作数空间,生成一个能匹配 ConstantArrayBuilder (即常量池)中预留的操作数(的索引值)大小的字节码。在打补丁时,如果偏移正好与预留的立即操作数大小相符,则取消 ConstantArrayBuilder 中的预留空间;否则,常量池预留空间被确认修改为跳转偏移值,跳转字节码和操作数被打补丁变为 “使用常量池中的跳转偏移值” 来跳转。
4.4 局部控制流
JavaScript 在语言级别上具有通常必备的控制流原语集,比如说 if 语句、if..else 语句、for 循环、while 循环、do 循环,以及 switch 语句。它还有特定的语言结构 for..in 遍历对象的属性和可 break 的命名块。这些控制流结构仅影响编译为字节码后函数内的执行。
BytecodeGenerator 将 AST 形式的 JavaScript 控制流语句转换为控制流构建类的实例,这些实例将生成相应的字节码。字节码级别的控制流由一组有条件和无条件跳转字节码组成。支持 JavaScript 的 for..in 语句需要额外的字节码来获取要被迭代的信息,以在集合的元素中行进。
为了便于创建控制流结构, BytecodeArrayBuilder 支持 “标签” 概念,它允许指定偏移量。当标签的位置已知时, BytecodeGenerator 调用 BytecodeArrayBuilder::Bind() 将当前位置绑定到标签上。在生成向前跳转的代码时, BytecodeGenerator 可以在标签被绑定之前引用它。 BytecodeArrayBuilder 在完成 BytecodeArray 的生成之前会检查字节码中引用到的所有标签都已经被绑定过。生成跳转的目标偏移量作为字节码或常量池中的立即操作数出现,不支持跳转到动态计算的值,比如说跳转到寄存器中的偏移量。
下面是 if..else 语句生成控制流的示例:

if..else 是生成器生成的最简单的控制流结构。对于更复杂的控制流结构,如循环和可 break 的块, BytecodeGenerator 会使用控制流构建器和控制作用域。
所有的循环使用相同的控制流构建器 LoopBuilder 的不同实例。 LoopBuilder 拥有一组标签用于循环条件、循环头、continue/next 目标,以及循环结束。循环语句的访问器生成循环头、循环条件和循环结束的标签,同时它也通过调用 BytecodeGenerator::VisitIterationBody 来访问迭代体中的语句。访问器主体在 BytecodeGenerator 中实例化一个 ControlScopeForIteration 并将它压到栈上,然后访问循环体中的语句。当命中一个 break 语句或者 continue 语句时,这些语句的访问器会查看当前的 ControlScopeForIteration 并发出 break (或 continue) 信号。控制作用域随后在与之关联的 LoopBuilder 上调用相应的方法,生成跳转到相关标签的指令。
ControlFlowBuilder 类保证了生成的字节码与源代码拥有相同的控制流顺序。这个自然的顺序意味着字节码中生成反向分支的唯一时机,是在循环语句中返回到循环的顶部。这个顺序也意味着在将字节码转换成 TurboFan 编译器的图格式时,不需要进行额外的循环分析。图构建的分支分析只需识别跳转的位置及其目标。
4.5 异常处理
TODO (原作者未完成)
5. 代码解释执行
Ignition 解释器是基于寄存器 (register-based)、间接线形调度 (indirect threaded) 的解释器。从其它 JavaScript 代码进入解释器的入口点是内置的 InterpreterEntryTrampoline stub。这个内置 stub 会初始化合适的栈帧,并在调度到被调用的函数第一个字节码前,加载合适的值到预留的机器寄存器中(比如:字节码指针、解释器调度表指针)。
5.1 栈帧布局和预留机器寄存器
解释器的栈帧布局如下图所示:
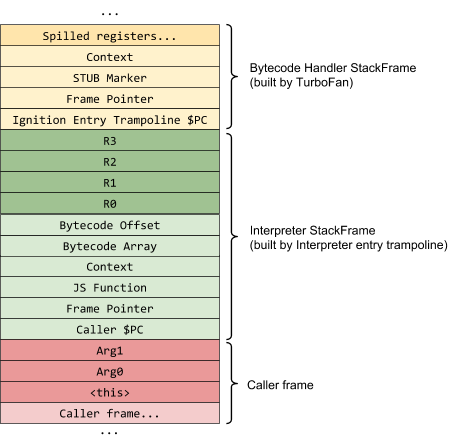
解释器栈帧被内置的 InterpreterEntryTrampoline stub 创建,它将每帧中固定的值(调用者 PC、帧指针、JSFunction、Context、字节码数组、字节码偏移)压栈,然后在栈帧中为寄存器文件( BytecodeArray 对象包含一个入口,可告知 stub 该函数所需的栈帧是多大)分配空间。然后它将寄存器文件中所有的寄存器写为 undefined ,以保证 GC 在遍历栈时,不会遇到非法的(即未被标记的,non-tagged)指针。
内置的 InterpreterEntryTrampoline stub 会初始化解释器用到的一些固定的机器寄存器,它们是:
kInterpreterAccumulatorRegister: 存储隐式的累加器解释器寄存器;kInterpreterBytecodeArrayRegister: 指向正在被解释执行的BytecodeArray对象起始位置;kInterpreterBytecodeOffsetRegister:BytecodeArray中当前正在执行的偏移(实质上就是字节码 PC);kInterpreterDispatchTableRegister: 指向解释器调度表,用于调度到下一个字节码处理程序;kInterpreterRegisterFileRegister: 指向寄存器文件的起始位置(很快将被移除,因为 TurboFan 可以直接使用父帧指针);kContextRegister: 指向当前的 Context 对象(很快将被移除,所有地方将通过解释器寄存器Register::current_context()来访问)。
随后调用字节码数据流中第一个字节码的字节码处理程序。上面初始化过的寄存器可被字节码处理程序作为 TurboFan 参数结点使用,因为字节码调度的调用规约为每个固定的机器寄存器指定了关联的参数。
如果字节码处理程序比较简单,没有调用其它任何函数(除了调度操作中的尾调用),那么 TurboFan 就可以忽略该字节码处理程序栈帧的创建。不过,在一些更复杂的字节码处理程序中,TurboFan 在进入字节码处理程序执行时会创建一个新的 stub,这个帧将仅仅保存 TurboFan 溢出的机器寄存器的值(比如,在函数调用中,“被调用者” 保存的寄存器),而不需要一个固定的帧。与解释执行的函数关联的所有状态,都被存放在解释执行的父帧中。
5.2 解释器寄存器访问
如上面所描述的,所有的局部变量、临时变量都在字节码的生成期间,在函数栈帧的寄存器文件中被分配为确定的寄存器。这些变量以及函数的参数,可以当做解释器寄存器被字节码处理程序访问。被字节码处理程序所操作的寄存器,在字节码流中被作为字节码的操作数。它的索引是从寄存器文件的起始开始、基于字的偏移量,它可以是正数(访问栈上寄存器文件上方的内容,比如函数的参数)或者负数(访问函数在寄存器文件中申请的局部变量)。解释器通过将操作数的索引缩放为单字节偏移量来访问给定的寄存器,然后在 “ kInterpreterRegisterFileRegister + 偏移量” 的内存位置加载或写入数据。
5.3 宽操作数
将生成的字节码大小最小化,是 Ignition 主要的推动因素,因此字节码格式要能支持不同宽度的操作数。Ignition 使用前置特定的字节码来支持更宽的操作数。Ignition 支持固定宽度操作数和可缩放宽度操作数,可缩放宽度操作数的大小根据前置字节码按比例缩放。
固定宽度操作数用于运行时调用识别码(16 位)和标志操作数(8 位)。寄存器操作数、立即操作数、索引操作数,以及寄存器个数操作数都基于 8 位大小,并且可以向上缩放到 32 位宽度。
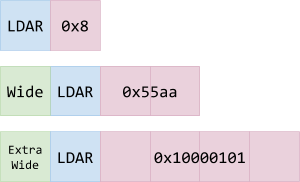
Wide 前置字节码让可缩放的操作数宽度加倍,变成 16 位宽; ExtraWide 前缀将宽度变成 4 倍,达到 32 位。
为了支持前置调度,字节码调度表中包含可缩放的操作数的条目,每组缩放偏移 256,也就是说 0-255 间的索引对应无缩放的字节码,256-511 对应有 Wide 前缀的字节码,512-767 对应有 ExtraWide 前缀的字节码。
在早期的 Ignition 设计中,将宽字节码放到了同一个 8 位空间中,这个做法限制了剩余可用字节码的数量,这些余下的将可能用于其它目的,比如字节码的特化;该设计还有一个详细的寄存器转换方案,用于访问宽寄存器操作数,因为它不可能让所有的字节码都有可缩放的版本。使用前置字节码的方案更简洁,并且这个 1 字节的消耗仅在使用到时才产生,在 Octane-2.1 基线测试中 size 开销不到 1%。
5.4 JS 调用
调用其它的 JS 函数由 Call 字节码处理。 BytecodeGenerator 保证了传给函数调用的参数在一组连续的寄存器中,然后执行 Call 字节码,该字节码的第一个寄存器操作数指定了 “保存被调用者的寄存器”,第二个寄存器操作数指定了 “保存参数起始位置的寄存器”,第三个操作数指定了 “传递的参数数量”。
解释器的 Call 字节码处理程序将当前字节码的偏移量更新到解释执行帧的字节码偏移 stack slot 中。这样让遍历栈的代码能计算出栈里面各帧的字节码 PC。然后调用 InterpreterPushArgsAndCall 内置指令,将被调用者、第一个参数寄存器的内存位置、参数的数量传递过去。随后内置的 InterpreterPushArgsAndCall 复制 <first_arg_register>...<first_arg_register + count> 范围内的值,将它们压到栈的末尾。然后调用内置的 Call ,和 full-codegen 用到的内置指令相同,用于对给出的被调用者求值,以获取调用的目标地址。调用解释执行的函数和调用 JIT 函数被同样处理 —— 内置的 Call 加载 JSFunction 的代码入口属性值,它指向被解释执行函数的内置 InterpreterEntryTrampoline stub,随后调用 InterpreterEntryTrampoline 重新进入解释器。
当解释执行的函数返回时,解释器在尾部调用内置的 InterpreterExitTrampoline stub,它会销毁栈帧,将控制权返回给主调函数,在字节码返回时,累加器中保存的值被作为返回值返回。
5.5 属性加载和存储
字节码通过内联缓存 (IC) 在 JS 对象上加载和存储属性。字节码处理程序和 JIT 代码 (例如 full-codegen) 一样,调用相同的 LoadIC 和 StoreIC 代码 stub。由于 Load/StoreIC 不再在代码上打补丁(而是在 TypeFeedbackVector 上操作),这意味着相同的 IC 可以同时给 JIT 代码和 Ignition 使用。
字节码处理程序将函数的 TypeFeedbackVector 以及与操作关联的 AST 节点的类型反馈 slot 一起传给相应的 IC stub。IC stub 同目前的 full-codegen 编译器一样,会更新 TypeFeedbackVector 中的条目,进行类型反馈学习,以被随后的优化编译使用。
5.6 二元操作
对于二元操作 BinaryOps 和其它的一元操作 UnaryOps (例如 ToBoolean ),现在 full-codegen 是使用打了机器码补丁的 IC。这些 IC 我们不能用在 Ignition 中,因为它们会给字节码处理程序代码打补丁(而它不是某个具体函数的调用现场)。因此,我们目前没有为二元和一元操作收集任何的类型反馈。
在目前,大多数的二元和一元操作是调用运行时函数来执行指定的操作。我们正在用 CodeStubAssembler 写成的 stub 来替换这些运行时调用,这些 stub 将普通的场景内联执行,仅在更复杂的情形下才会调用到外部的运行时。目前我们称之为 stub,然而由于它们使用 CodeStubAssembler 写成,我们可以很容易地将这些代码内联到解释器的字节码处理程序中。
在将来的优化中,我们可能利用给实际的字节码反向打补丁,来将给定的操作指向特化的字节码处理程序(例如,将内联的 SmiAdd 作为一个特化的字节码),不过这取决于我们最终做出的关于在 Ignition 中收集 BinaryOps 和 UnaryOps 的类型反馈的决定。
6. TurboFan 字节码图生成器
BytecodeGenerator 创建的 BytecodeArray 包含了所有需要的信息,传给 TurboFan 创建 TurboFan 编译图,由 BytecodeGraphBuilder 实现。
首先, BytecodeGraphBuilder 遍历字节码进行一些基础的分支分析,以找到向前和向后分支的目标字节码。它们用于在创建 TurboFan 图时,在 BytecodeGraphBuilder 中初始化合适的循环头环境。
然后, BytecodeGraphBuilder 再次遍历字节码,访问每个字节码,并为每个字节码调用特定的字节码访问器,字节码访问器函数从 BytecodeArray 中读取字节码操作数,然后向 TurboFan 图中增加操作来执行该字节码的操作。很多字节码在 TurboFan 中都有一个现成的 JSOperator 直接映射。
BytecodeGraphBuilder 维护着一个环境,跟踪了哪些节点表示着存储在寄存器文件中每个寄存器的值(包含累加器寄存器)。这个环境同时也跟踪着当前的 Context 对象(它通过 Push/PopContext 字节码更新)。当访问器访问一个字节码,需要从寄存器中读取值时,它从环境中查找出与该寄存器关联的节点,然后将它作为正在为当前字节码创建的 JSOperator 节点的输入节点。类似的,对于那些输出值到寄存器或累加器的操作,访问器在完成操作时,使用新的节点更新环境中寄存器。
6.1 解优化
JavaScript 的操作可能在执行过程中触发从优化代码返回到未优化的字节码的解优化行为。为了支持解优化, BytecodeGraphBuilder 需要跟踪解释器栈帧的状态,以便在解优化时可以重建解释器栈帧,并从解优化的地方重新进入函数。
上述的环境已经做到了这一点,通过保持跟踪每个寄存器在字节码执行的每个点所关联的节点。 BytecodeGraphBuilder 在 FrameNode 节点中为可能触发解优化的 JSOperator 节点检查它的信息(要么是 激进的 —— 基于节点执行前的状态检查,或者是 延迟的 —— 在节点执行完后检查)。
由于每个字节码映射到了一个单独的 JSOperator 节点,这意味着我们只能解优化到一个字节码的开头或者末尾。因此,我们使用字节码偏移量来作为解优化点中的 BailoutId 。当 TurboFan 生成代码处理潜在的解优化时,它会序列化一条 TranslatedState 记录来描述怎么为当前解优化点重建解释器帧,它基于该解优化点的 FrameState 节点。当该解优化点被命中时,解释器帧通过使用这条 TranslatedState 记录被创建出来,然后通过内置的 InterpreterNotifyDeoptimized 运行时重新从合适的字节码偏移进入解释器。
7. 调试支持
为了支持解释器执行调试器断点代码,调试器复制了函数中的 BytecodeArray 对象,然后将断点目标位置的任意字节码替换为特定的 DebugBreak 字节码。由于所有的字节码至少是一个字节,没必要在字节码流中申请额外的空间,来保证可用于断点设置。对于每种大小的字节码,有不同的 DebugBreak 字节码变种来保证 BytecodeArray 仍然可以被正确迭代。同时也有 DebugBreakWide 和 DebugBreakExtraWide 字节码,它同样作为断点,也作为下一个字节码的前缀,同 Wide 或 ExtraWide 变种(与 Wide 和 ExtraWide 字节码一样,作用于非断点代码)。
一旦断点被命中,解释器调用到调试器中。调试器可以通过查看函数的真实 BytecodeArray 来恢复执行,调度到被 DebugBreak 字节码所替换的真实字节码。
更多的细节见 Ignition 调试支持设计文档。
7.1 源码位置
源码位置在 BytecodeGenerator 生成字节码时一起生成。有两种类型的源码位置:声明位置和表达式位置。声明位置用于调试器在声明语句中单步执行,声明位置存在于:在关联的字节码被调度到之前调试器可以进入的位置。表达式位置用于当表达式中抛出异常时提供栈回溯信息。当异常被抛出时,调试器从产生异常的位置向后扫描,查找表达式位置,并用于栈回溯。

字节码生成过程需要为调试器和异常报告维护源码位置来保证它们正确工作。字节码生成过程中任何的优化都需要保证源码位置有相同的因果顺序。一些源码位置可以被消除,因为它们与一些不可能产生异常的字节码关联,或者是重复的。
7.2 性能分析支持
TODO (原作者未完成)
8. 将来的工作
(原作者未完成)
- TODO - 描述可能的专用字节码补丁优化
- TODO - 描述可能的超级字节码
- TODO - 描述二元操作的类型反馈
附录 A:字节码表
text
【前置字节码】
Wide
ExtraWide
【累加器加载】
LdaZero
LdaSmi
LdaUndefined
LdaNull
LdaTheHole
LdaTrue
LdaFalse
LdaConstant
【加载/存储全局变量】
LdaGlobal
LdaGlobalInsideTypeof
StaGlobalSloppy
StaGlobalStrict
【Context 操作】
PushContext
PopContext
LdaContextSlot
StaContextSlot
【一元操作】
Inc
Dec
LogicalNot
TypeOf
DeletePropertyStrict
DeletePropertySloppy
【控制流】
Jump
JumpConstant
JumpIfTrue
JumpIfTrueConstant
JumpIfFalse
JumpIfFalseConstant
JumpIfToBooleanTrue
JumpIfToBooleanTrueConstant
JumpIfToBooleanFalse
JumpIfToBooleanFalseConstant
JumpIfNull
JumpIfNullConstant
JumpIfUndefined
JumpIfUndefinedConstant
JumpIfNotHole
JumpIfNotHoleConstant
【加载/存储查找 slot】
LdaLookupSlot
LdaLookupSlotInsideTypeof
StaLookupSlotSloppy
StaLookupSlotStrict
【寄存器传输】
Ldar
Mov
Star
【LoadIC 操作】
LoadIC
KeyedLoadIC
【StoreIC 操作】
StoreICSloppy
StoreICStrict
KeyedStoreICSloppy
KeyedStoreICStrict
【二元操作】
Add
Sub
Mul
Div
Mod
BitwiseOr
BitwiseXor
BitwiseAnd
ShiftLeft
ShiftRight
ShiftRightLogical
【For..in 支持】
ForInPrepare
ForInDone
ForInNext
ForInStep
【栈保护检查】
StackCheck
【非局部控制流】
Throw
ReThrow
Return
【非法字节码】
Illegal
【调用】
Call
TailCall
CallRuntime
CallRuntimeForPair
CallJSRuntime
【内部函数】
InvokeIntrinsic
【New 操作】
New
【Test 操作】
TestEqual
TestNotEqual
TestEqualStrict
TestLessThan
TestGreaterThan
TestLessThanOrEqual
TestGreaterThanOrEqual
TestInstanceOf
TestIn
【类型转换操作】
ToName
ToNumber
ToObject
【Literals】
CreateRegExpLiteral
CreateArrayLiteral
CreateObjectLiteral
【闭包申请】
CreateClosure
【参数申请】
CreateMappedArguments
CreateUnmappedArguments
CreateRestParameter
【调试支持】
DebugBreak0
DebugBreak1
DebugBreak2
DebugBreak3
DebugBreak4
DebugBreak5
DebugBreak6
DebugBreakWide
DebugBreakExtraWide
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
附录 B:参考资料
- Threaded Code, in Wikipedia entry, https://en.wikipedia.org/wiki/Threaded_code
- Revolutionizing Embedded Software, Kasper Verdich Lund and Jakob Roland Andersen, in Master’s Thesis at University of Aarhus, http://verdich.dk/kasper/RES.pdf.
- Inside JavaScriptCore's Low-Level Interpreter, Andy Wingo’s blog, https://wingolog.org/archives/2012/06/27/inside-javascriptcores-low-level-interpreter
- SquirrelFish, David Manelin’s blog, https://blog.mozilla.org/dmandelin/2008/06/03/squirrelfish/
- Context Threading, Marc Berndl, Benjamin Vitale, Mathew Zaleski, and Angela Demke Brown, in CGO ’05: Proceedings of the international symposium on Code generation and optimization, http://www.cs.toronto.edu/syslab/pubs/demkea_context.pdf (also Mathew Zeleski’s thesis http://www.cs.toronto.edu/~matz/dissertation/)
- Optimizing Indirect Branch Prediction Accuracy in Virtual Machine Interpreters, M. Anton Ertl and David Gregg, in PLDI’03, http://www.eecg.toronto.edu/~steffan/carg/readings/optimizing-indirect-branch-prediction.pdf
- The Case for Virtual Register Machines, Brian Davis, Andrew Beatty, Kevin Casey, David Gregg, and John Waldron, in Interpreters, Virtual Machines, and Emulators (IVME’03), http://**dl.acm.org/citation.cfm?**id=858575
- Virtual Machine Showdown: Stack vs Registers, Yuhne Shi, David Gregg, Andrew Beatty, and M. Anton Ertl, in VEE’05. https://www.usenix.org/legacy/events/vee05/full_papers/p153-yunhe.pdf
- vmgen - A Generator of Efficient Virtual Machine Interpreters, M. Anton Ertl, David Gregg, Andreas Krall, and Bernd Paysan, in Software: Practice and Experience, 2002. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.16.7676&rep=rep1&type=pdf
- The Self Bibliography, https://www.**cs.ucsb.edu/~urs/oocsb/**self/papers/papers.html
- Interpreter Implementation Choices, http://realityforge.org/code/virtual-machines/2011/05/19/interpreters.html
- Optimizing an ANSI C Interpreter with Superoperators, Todd A. Proebstring, in POPL’95, http://**dl.acm.org/citation.cfm?**id=199526
- Stack Caching for Interpreters, M Anton Ertl, in SIGPLAN ’95 Conference on Programming Language Design and Implementation, http://www.csc.uvic.ca/~csc485c/Papers/ertl94sc.pdf
- Code sharing among states for stack-caching interpreter, Jinzhan Peng, Gansha Wu, Guei-Yuan Lueh, in Proceedings of the 2004 workshop on Interpreters, Virtual Machines, and Emulators, http://**dl.acm.org/citation.cfm?**id=1059584
- Towards Superinstructions for Java Interpeters, K. Casey, D. Gregg, M. A. Ertl, and A. Nisbet, in Proceedings of the 7th International Workshop on Software and Compilers for Embedded Systems, http://rd.springer.com/chapter/10.1007/978-3-540-39920-9_23
- Branch Prediction and the Perfomance of Interpreters - Don’t Trust Folklore, Erven Rohou, Bharath Narasimha Swamy, Andre Seznec. International Symposium on Code Generation and Optimization, Feb 2015, Burlingame, United States. https://hal.inria.fr/hal-00911146/document
参考
- Ignition Design Doc - Google Docs
- 【译】Ignition:V8 解释器 - 知乎
- Ignition: V8 Interpreter - 文档 - Jonsam's Docs
扩展
版权声明
本文转载自 Ignition:V8 解释器,原文为 Ignition Design Doc,所有版权归原作者所有。部分内容有删改。